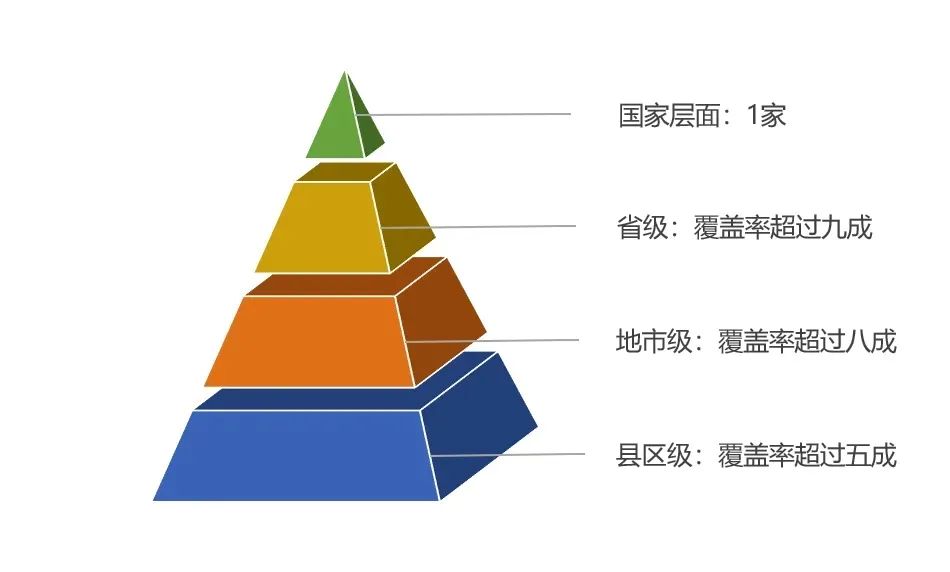
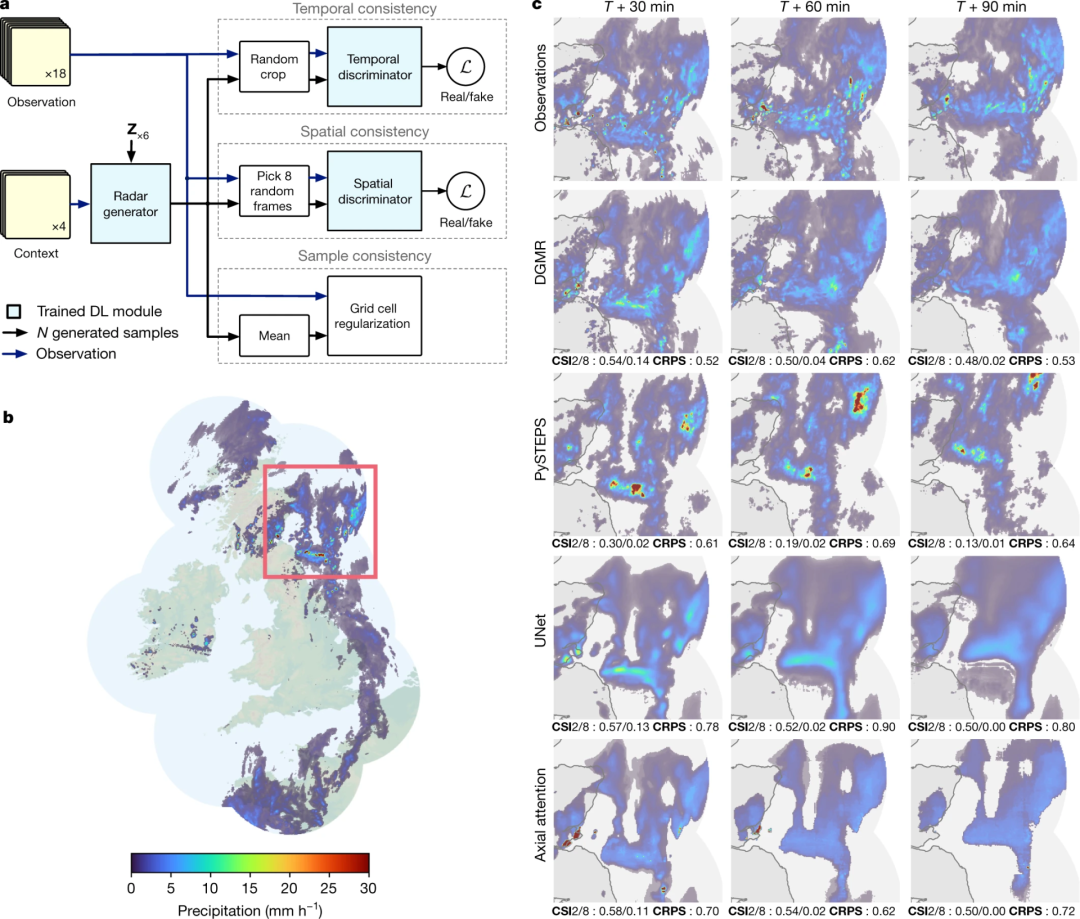
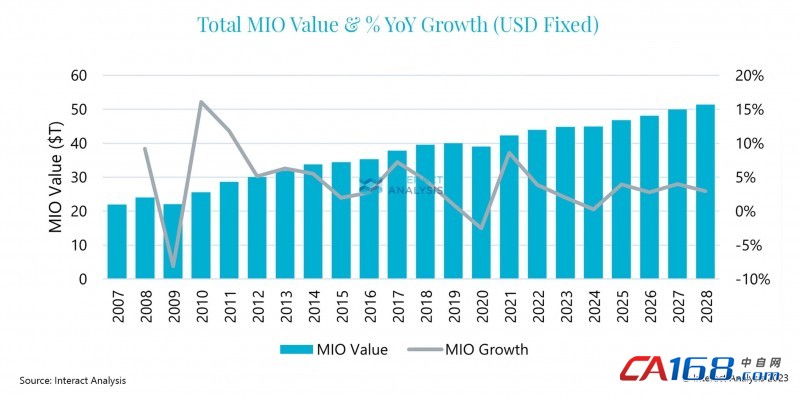
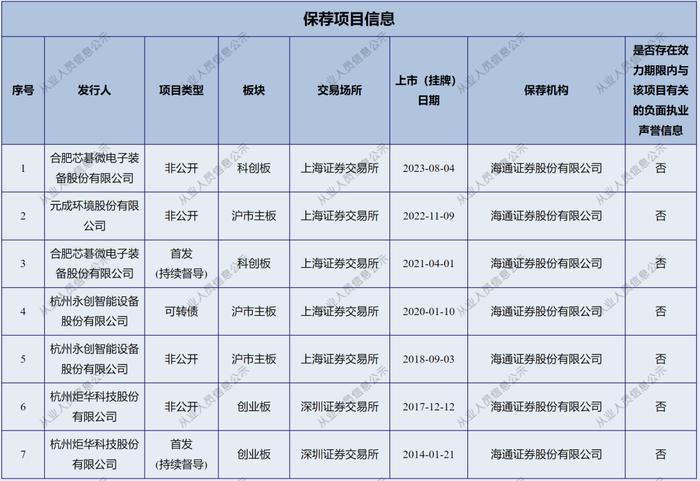
新华社北京7月25日电 对于人工智能(AI)大语言模型来说,通常给予的训练数据越多,模型就会越“聪明”。但英国《自然》杂志新发表的一项关于大模型的研究显示,如果只用AI生成的数据来训练大模型,会使模型性能下降、越练越“傻”。

图片来源于网络,如有侵权,请联系删除
英国牛津大学、剑桥大学等机构研究人员发现,如果在训练大模型时,只用AI生成的内容,会导致大模型出现不可逆的缺陷,逐渐忘记真实数据的分布,这被称为“模型崩溃”。
2024年4月23日,在德国汉诺威工博会上,参观者与一款智能机器人进行“石头剪子布”游戏。新华社记者任鹏飞摄研究人员首先使用大语言模型创建类似维基百科词条的文本,然后利用这个内容来训练该模型的新版本,并反复使用前代模型生成的文本训练更新的版本。随着AI生成的信息“污染”训练集,模型的输出逐渐失去意义。在模型的第九次迭代中,它完成了一篇关于英国教堂塔楼的文章,其中一段文字却在讲述野兔尾巴的多种颜色。
研究发现,导致“模型崩溃”的重要原因是,由于模型只能从其训练数据中采样,一些在第一代数据中本就低频出现的词汇,在每次迭代后出现的频率变得更低,而一些常见词汇出现的频率则逐渐增加。
这种变化的结果就是,模型逐渐无法正确模拟真实世界的复杂性。随着时间推移,这种错误会在迭代中被层层累积、逐渐放大,最终导致“模型崩溃”。这有点像生物学中“近亲繁殖”会导致后代缺陷,如果不能保证基因库的多样性,最终会导致一个物种的崩溃。
研究人员还发现,由于训练数据被“污染”而导致“模型崩溃”的情况不止发生在大语言模型中,高斯混合模型、图片生成器等也可能出现类似情况。
不过,应对“模型崩溃”并非束手无策。研究人员发现,如果能在模型微调过程中保留10%左右的真实数据,崩溃就会发生得更缓慢。还可使用水印技术,将AI生成的数据与真实数据区分开来,这需要大型科技公司的协作。此外,在AI生成的文本重新进入数据池之前,可由人类先筛选过滤。
【责任编辑:陈听雨】